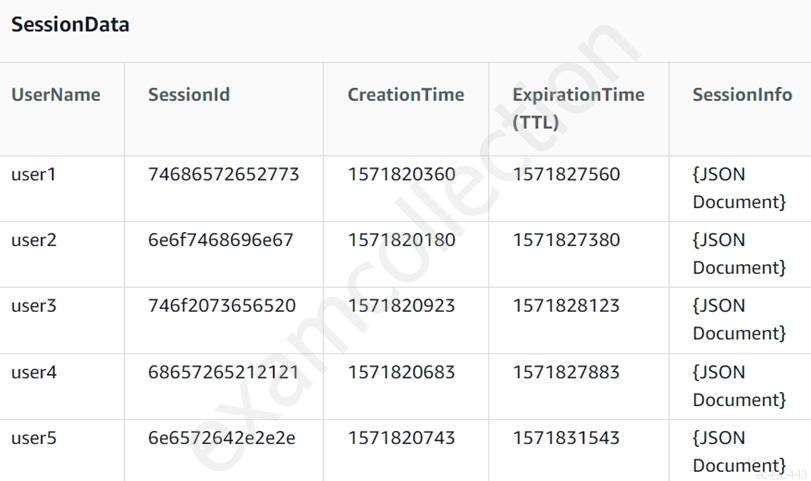
An ecommerce company uses Amazon DynamoDB as the backend for its payments system. A new regulation requires the company to log all data access requests for financial audits. For this purpose, the company plans to use AWS logging and save logs to Amazon S3
How can a database specialist activate logging on the database?
A. Use AWS CloudTrail to monitor DynamoDB control-plane operations. Create a DynamoDB stream to monitor data-plane operations. Pass the stream to Amazon Kinesis Data Streams. Use that stream as a source for Amazon Kinesis Data Firehose to store the data in an Amazon S3 bucket.
B. Use AWS CloudTrail to monitor DynamoDB data-plane operations. Create a DynamoDB stream to monitor control-plane operations. Pass the stream to Amazon Kinesis Data Streams. Use that stream as a source for Amazon Kinesis Data Firehose to store the data in an Amazon S3 bucket.
C. Create two trails in AWS CloudTrail. Use Trail1 to monitor DynamoDB control-plane operations. Use Trail2 to monitor DynamoDB data-plane operations.
D. Use AWS CloudTrail to monitor DynamoDB data-plane and control-plane operations.
How can a database specialist activate logging on the database?
A. Use AWS CloudTrail to monitor DynamoDB control-plane operations. Create a DynamoDB stream to monitor data-plane operations. Pass the stream to Amazon Kinesis Data Streams. Use that stream as a source for Amazon Kinesis Data Firehose to store the data in an Amazon S3 bucket.
B. Use AWS CloudTrail to monitor DynamoDB data-plane operations. Create a DynamoDB stream to monitor control-plane operations. Pass the stream to Amazon Kinesis Data Streams. Use that stream as a source for Amazon Kinesis Data Firehose to store the data in an Amazon S3 bucket.
C. Create two trails in AWS CloudTrail. Use Trail1 to monitor DynamoDB control-plane operations. Use Trail2 to monitor DynamoDB data-plane operations.
D. Use AWS CloudTrail to monitor DynamoDB data-plane and control-plane operations.