A company wants to classify user behavior as either fraudulent or normal. Based on internal research, a machine learning specialist will build a binary classifier based on two features: age of account, denoted by x, and transaction month, denoted by y. The class distributions are illustrated in the provided figure. The positive class is portrayed in red, while the negative class is portrayed in black.
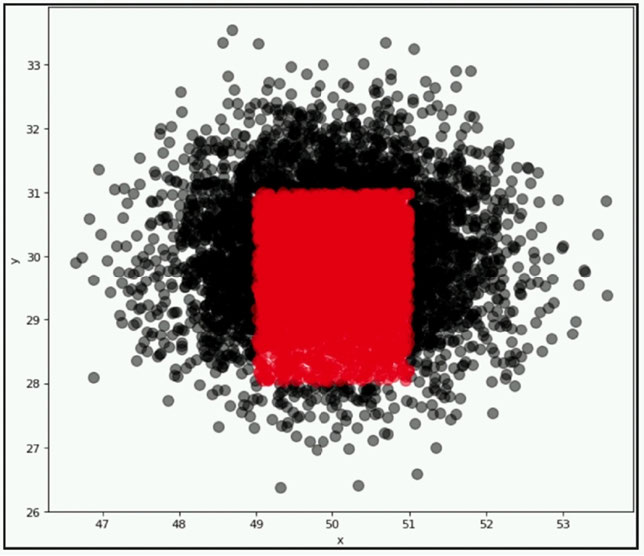
Which model would have the HIGHEST accuracy?
A. Linear support vector machine (SVM)
B. Decision tree
C. Support vector machine (SVM) with a radial basis function kernel
D. Single perceptron with a Tanh activation function
Which model would have the HIGHEST accuracy?
A. Linear support vector machine (SVM)
B. Decision tree
C. Support vector machine (SVM) with a radial basis function kernel
D. Single perceptron with a Tanh activation function